
Codigo Introduccion Deep Learning-UPSA
https://drive.google.com/open?id=1-Avc2xqiYpM7G1CZqXhgYpTZEud_kbbD …
Codigo Introduccion Deep Learning-UPSA
https://drive.google.com/open?id=1-Avc2xqiYpM7G1CZqXhgYpTZEud_kbbD …
This Youtube reproduction list is a fantastic place to understand what is a Tensor.
It goes all the way to explain how tensors are defined. It starts from vectors, linear maps, dual spaces, tensor product and finally they arrive to the definition of tensors.
Very clear!!
It is very interesting to see the connection between the different approaches to solve the linear regression problem.
The firs point of view is simply as an optimization problem. The normal approach is to try to minimize the residual (errors) sum of squares (RSS). In that way we arrive to the normal equations that solve the problem (least squares)(linear regression)(OLS). To minimize the expression we equal the gradient of the RSS to zero and solve it to obtain the parameters that achieves the minimum. If instead of the RSS we use the absolute value of the residuals we arrive to the LAD (least absolute deviation) solution. For this solution there is not a close form solution, instead you have to use a linear programming apprach to solve it. Both LAD or RSS use the minimization of a cost function.
When using a cost functions you can be lucky and have a close form solution (RSS case) or, more often, you arrive to a solution that involves an iterative process, either using gradient descent, stochastic gradient descent (using the gradient of the cost function) or some other method that uses both the gradient and the hessian of the cost fucntion (Newton method, quasi-Newton, …) (gradient descent)(finding minima)(gradient LAD)
Same results obtained by the optimization approach can be produced by other different means.
The predictor variable can be seen as a random variable produced by a function of the independent variables (deterministic) plus an error term (another random variable).
The pdf (probability density function) of the predictor random variable (the posterior distribution) will be similar to the pdf of the error term, except by a difference in the expected value that is provided by the linear relationship established on the independent variables.
If we assume that the error term has a gaussian pdf with zero mean and we try to determine the parameters of the linear function that maximize the log likelihood (MLE, maximum likelihood estimator) of the predicted values, conditioned on the independent data, we arrive to exactly the same solution that when optimizing the RSS cost function (see chapter 3 of the book: The Elements of Statistical Analysis, Hastie, Tibshirani)
The interesting point is that changing the pdf of the error term we arrive to different solutions.
If the error term has a Laplacian pdf and we use the same MLE strategy to estimate the parameters, we arrive to the same solution as when optimizing the least absolute value as a cost function.
When using different pdf distributions for the error term we arrive to different solutions.
To use a Laplacian pdf or any other long tail distribution provides a robust linear regression. The reason for that is that the error term distributon is able to incorporate outliers whithout having to change drastically its location (mean) parameters. When using a gaussian pdf this is not possible as the gaussian tolerates outliers badly (see chapter 7 of K.P. Murphy book: Machine Learning a probabilistic perspective).
When using the probabilistic perspective to the cost function minimization approach we have to minimize the expected value of the cost function as now both X and Y (independent and dependent variables) are random variables. Following this path we obtain that the best solution, in case of the square loss function, is the expected value of Y conditioned on X [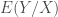
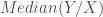

The bayesian solution gives the most insigth to the different elements that can take part in a linear regression.
To tell it shortly, the bayesian’s prior distribution takes care of the regularization term and the bayesian’s likelihood distribution handles the errors and outliers.
Regularization is a term used in machine learning for different techniques to manage the overfitting problem. This is done, for example, adding a additional (regularization) term to a cost function in such a way that increasing the values of the parameters of the model gives a penalty to the cost function.
Why reducing the values of the parameters of a model is good to control overfitting?
Consider a model with a lot of parameters (so, prone to overfit) but with all the parameters equal to zero (regularization term dissapears!). Well, this model is complex (lots of parameters) but as all the parameters are zero it is actually not complex anymore, that is actually as not having any model at all.
This is the way that the regularization term controls overfitting of a complex model.
How the prior of a bayesian model is related to regularization? Well, if we assume that our parameters prior is a gaussian with zero means and a very small variance, we are telling that we are pretty sure that the parameters will be close to zero. So, we are actually adding a regularization term.
Otherwise, if we impose the prior of the parameters distribution to be a uniform distribution, we don’t add any regularization term. A uniform prior on a bayesian model will arrive to the same OLS results obtained by the Normal Equations, without regularization (Table 7.1 of Murphy’s book) .
If we do the maths (chapter 7.5.1 of Murphy’s book) the result of adding a gaussian prior is equivalent to adding a ridge regression term to our linear regression model. If, instead we add a laplacian prior we have a different kind of regularization that is called lasso.
The likelihood distribution in the bayesian model has the same effect that the error term pdf in the probabilistic approach. Using diferent likelihoods distributions we can control our model robustness to outliers.
Great R code repository for statistical modeling, with code for all the linear models variants: http://www.uni-kiel.de/psychologie/rexrepos/posts/regression.html
This is the best introduction to NoSQL, I have seen
I was quite surprised when I learnt that a maximum likelihood estimate follows asymptotically a normal distribution with the mean being the estimated value and the variance being the inverse of the Fisher Information multiplied by the number of observations.
Asymptotically means when you have a big number of samples to calculate your ML estimate.
This is quite a remarkable fact. Some information:
http://math.arizona.edu/~jwatkins/o-mle.pdf (page 10)
This entry on p-hacking and the issues with the use of p-values is very good:
http://stats.stackexchange.com/questions/200745/how-much-do-we-know-about-p-hacking-in-the-wild
This blog is great as a reference to missing value imputation in R
Excellent
http://info.usherbrooke.ca/hlarochelle/neural_networks/content.html
Very good
https://www.coursera.org/course/neuralnets
Fantastic (made by Google)
https://www.udacity.com/course/deep-learning–ud730
Splendid (more specialized on NLP)
http://cs224d.stanford.edu/syllabus.html
And take a look to this online resources:
http://www.deeplearningbook.org/
http://deeplearning.stanford.edu/wiki/index.php/UFLDL_Tutorial
http://deeplearning.stanford.edu/tutorial/
http://deeplearning.net/tutorial/
http://deeplearning.net/reading-list/tutorials/
These tutorials are fantastic for econometrics, at all levels:
undergraduate:
graduate level:
Great places for Exploratory Factor Analysis (conceptual):
